Technical Description
• Architecture
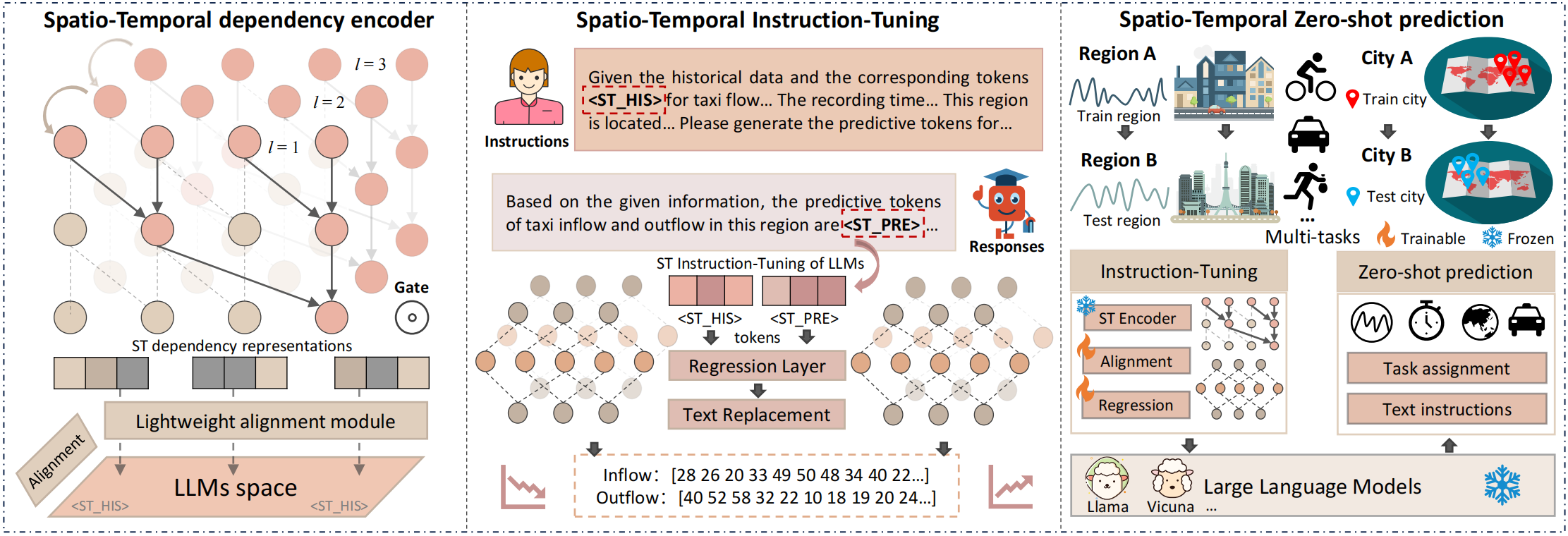
Figure 1: The overall architecture of the proposed spatio-temporal language model UrbanGPT.
- Spatio-Temporal Dependency Encoder. Although large language models demonstrate exceptional proficiency in language processing, they face challenges in comprehending the time-evolving patterns inherent in spatio-temporal data. To overcome this limitation, we propose enhancing the capability of large language models to capture temporal dependencies within spatio-temporal contexts. This is accomplished by integrating a spatio-temporal encoder that incorporates a multi-level temporal convolutional network. By doing so, we enable the model to effectively capture the intricate temporal dependencies across various time resolutions, thereby improving its understanding of the complex temporal dynamics present in the spatio-temporal data. Specifically, our spatio-temporal encoder is composed of two key components: a gated dilated convolution layer and a multi-level correlation injection layer.
- Spatio-Temporal-Text Alignment. In order to enable language models to effectively comprehend spatio-temporal patterns, it is crucial to align textual and spatio-temporal information. This alignment allows for the fusion of different modalities, resulting in a more informative representation. By integrating contextual features from both textual and spatio-temporal domains, we can capture complementary information and extract higher-level semantic representations that are more expressive and meaningful. To achieve this objective, we utilize a lightweight alignment module to project the spatio-temporal dependencies representations.
- Spatio-Temporal Prompt Instructions. In scenarios involving spatio-temporal prediction, both temporal and spatial information contain valuable semantic details that contribute to the model's understanding of spatio-temporal patterns within specific contexts. For instance, traffic flow in the early morning differs significantly from rush hour, and there are variations in traffic patterns between commercial and residential areas. As a result, we recognize the potential of representing both temporal and spatial information as prompt instruction text. We leverage the text understanding capabilities of large language models to encode this information, enabling associative reasoning for downstream tasks.
- Spatio-Temporal Instruction-Tuning of LLMs. To fine-tune LLMs using instructions to generate spatio-temporal forecasts in textual format poses two challenges. Firstly, spatio-temporal forecasting typically relies on numerical data, which differs in structure and patterns from natural language that language models excel at processing, focusing on semantic and syntactic relationships. Secondly, LLMs are typically pre-trained using a multi-classification loss to predict vocabulary, resulting in a probability distribution of potential outcomes. This contrasts with the continuous value distribution required for regression tasks. To address these challenges, UrbanGPT adopts a different strategy by refraining from directly predicting future spatio-temporal values. Instead, it generates forecasting tokens that aid in the prediction process. These tokens are subsequently passed through a regression layer, which maps the hidden representations to generate more accurate predictive values.

Figure 2: Illustration of spatio-temporal prompt instructions encoding the time- and location-aware information.
• Experiments
Zero-Shot Prediction Performance
In this section, we thoroughly evaluate the predictive performance of our proposed model in zero-shot scenarios. Our objective is to assess the model's effectiveness in predicting spatio-temporal patterns in geographical areas that it has not encountered during training. This evaluation encompasses both cross-region and cross-city settings, allowing us to gain insights into the model's generalization capabilities across different locations.
(1) Prediction on Unseen Regions within a City
Cross-region scenarios entail using data from certain regions within a city to forecast future conditions in other regions that have not been encountered by the model. The results highlight the exceptional performance of our proposed model in both regression and classification tasks on various datasets, surpassing the baseline models in zero-shot prediction.
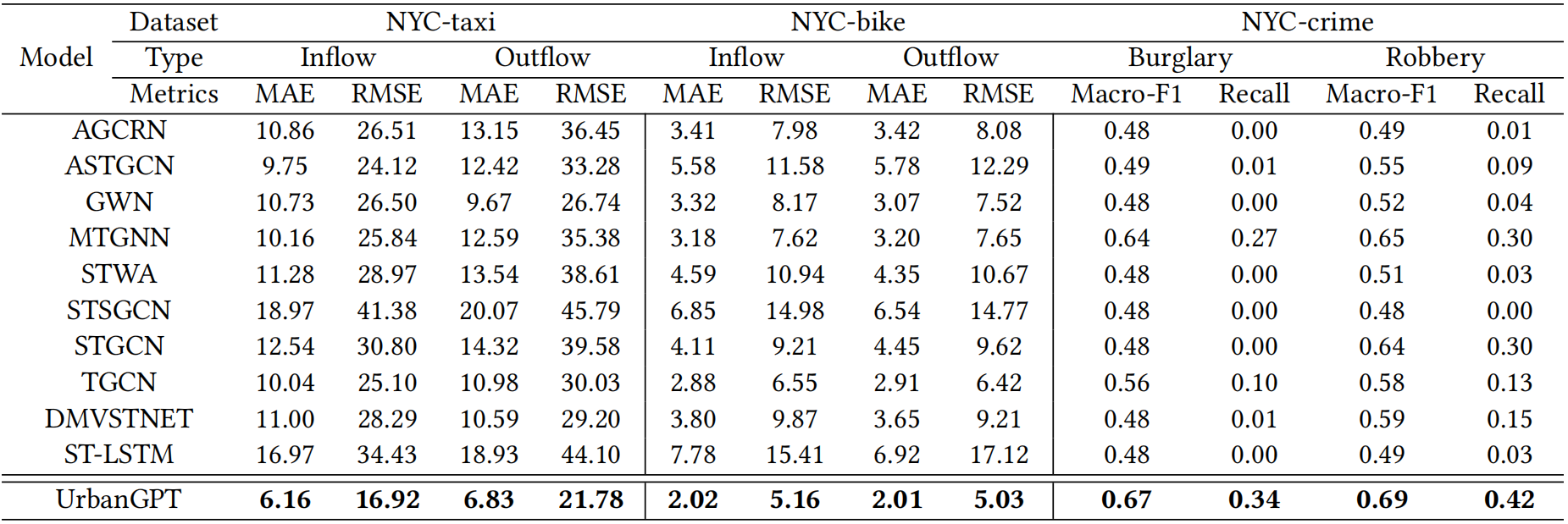
Figure 3: Our model’s performance in zero-shot prediction is evaluated on three diverse datasets: NYC-taxi, NYC-bike, and NYC-crime, providing a comprehensive assessment of its predictive capabilities in unseen situations.
(2) Cross-City Prediction Task
To assess the performance of our model in cross-city prediction tasks, we conducted tests on the CHI-taxi dataset, which was not seen during the training phase.

Figure 4: Time step-based prediction comparison experiment conducted on the CHI-taxi dataset.
Classical Supervised Prediction Task
This section examines the predictive capabilities of our UrbanGPT in end-to-end supervised prediction scenarios, as presented in Figure 5.
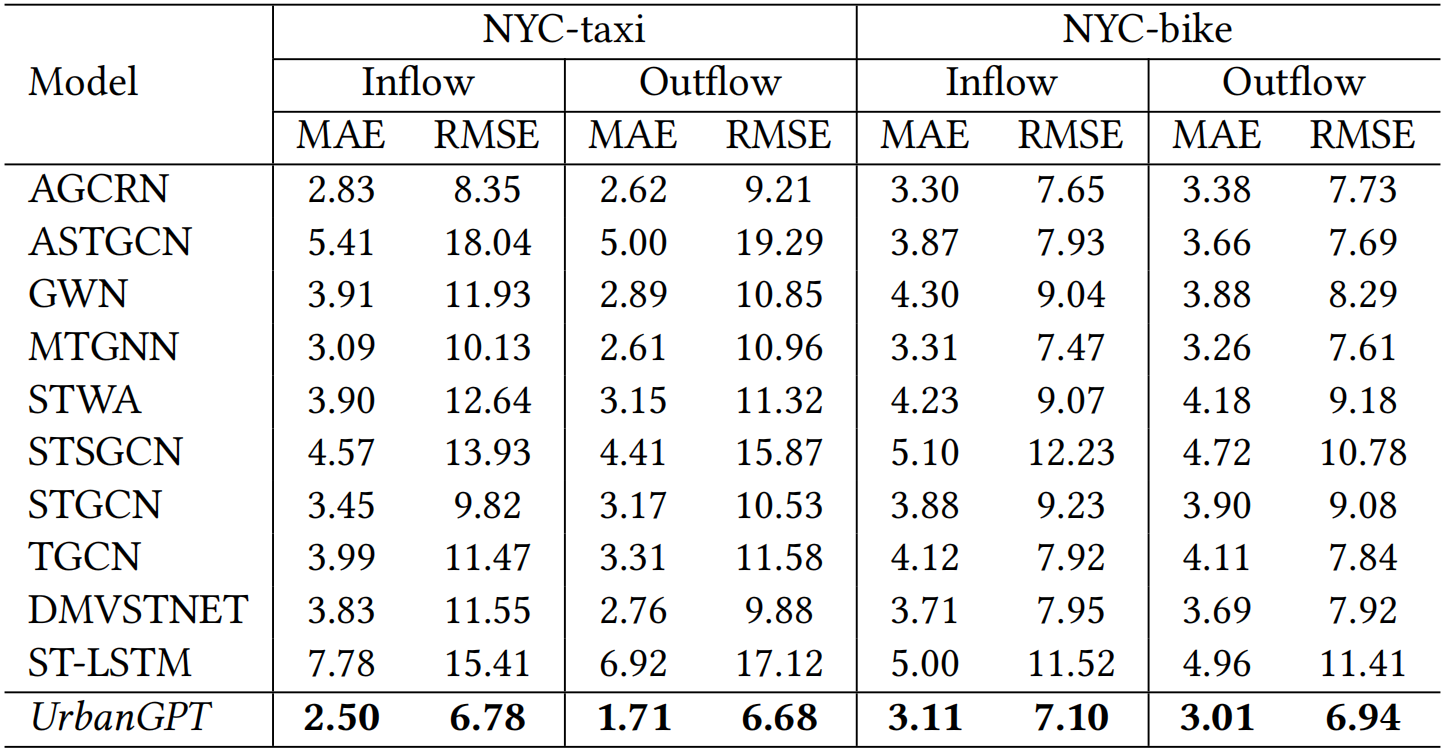
Figure 5: Evaluation of performance in the end-to-end supervised setting on the NYC-taxi and NYC-bike datasets.
Ablation Study
This section investigates the impact of different key components on the performance of our model, as illustrated in Figure 6. Our rigorous testing primarily revolves around the zero-shot scenario using the NYC-taxi dataset.
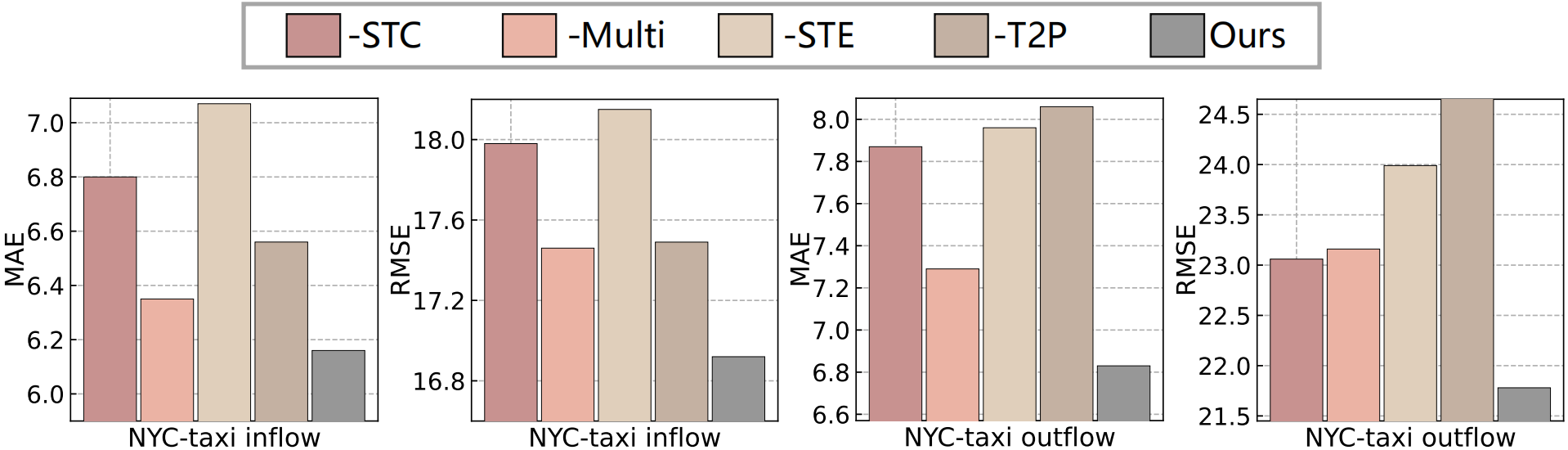
Figure 6: Ablation study of our proposed UrbanGPT.
Model Robustness Study
In this section, we focus on evaluating the robustness of our UrbanGPT across different spatio-temporal pattern scenarios. We categorize regions based on the magnitude of numerical variations, such as taxi flow, during a specific time period. Lower variance indicates stable temporal patterns, while higher variance suggests diverse spatio-temporal patterns in active commercial zones or densely populated areas.
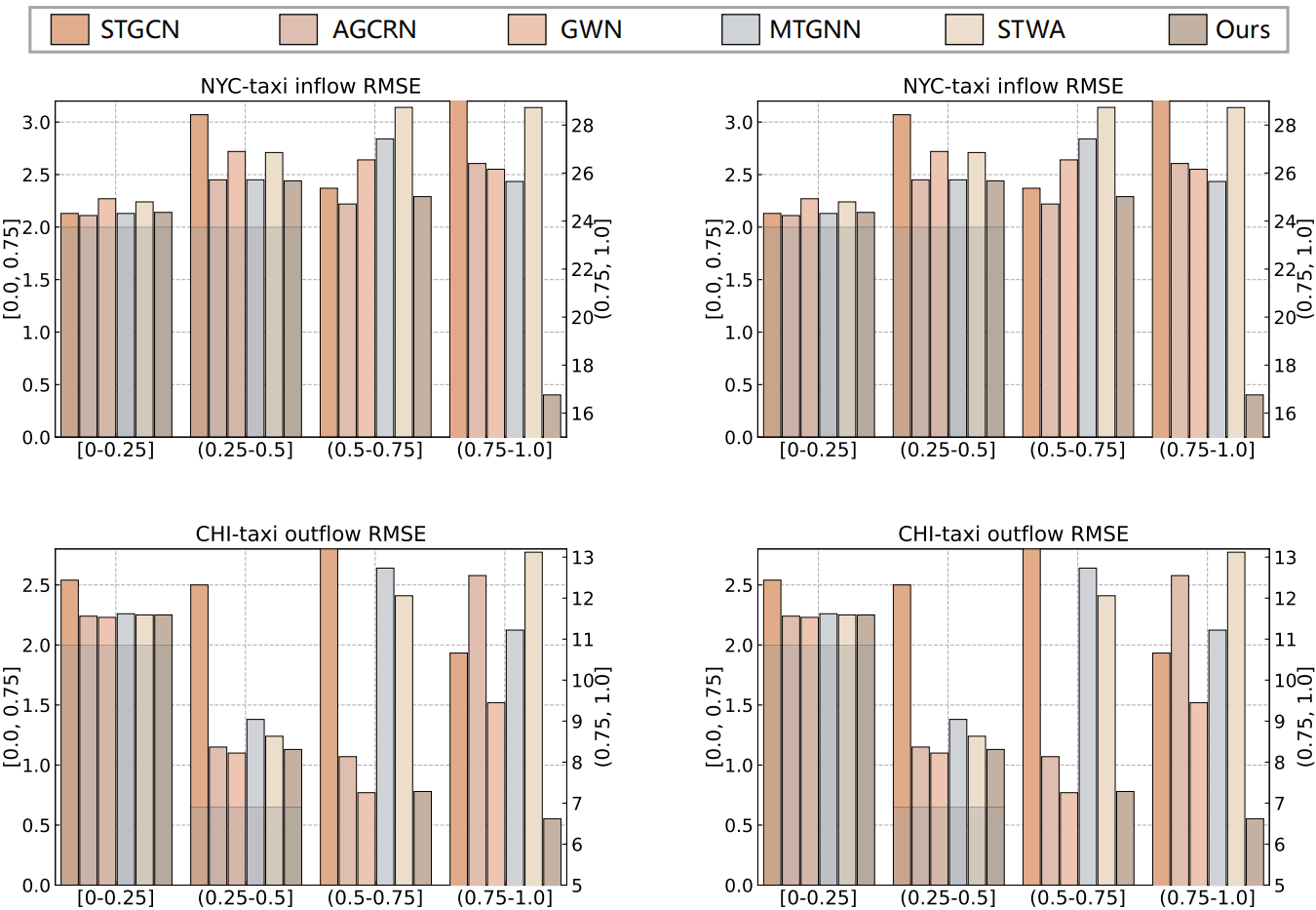
Figure 7: Robustness study of the UrbanGPT model.